Shaping Tomorrow’s disaster recovery and business continuity plan is based on the principles of N+1 Redundant Servers, whereby components (N) have at least one independent backup component (+1). Have a look at this example diagram of our N+1 Redundant systems and it puts things into a clearer perspective.
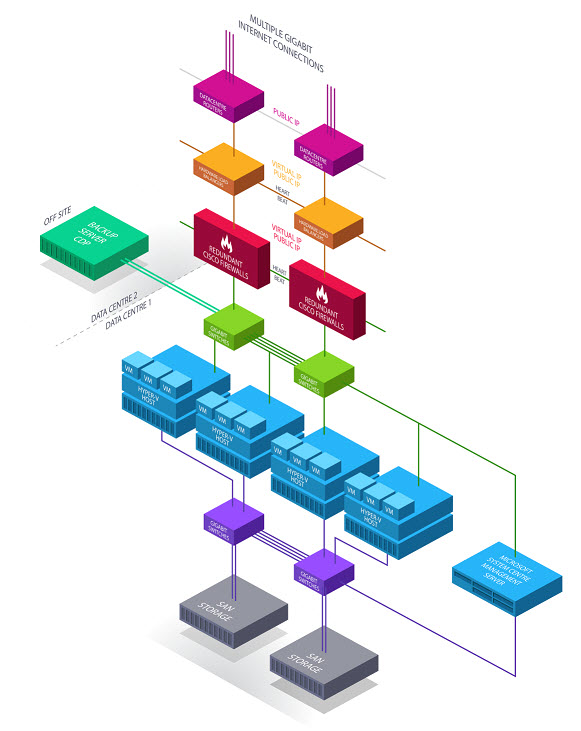
Behind the dual Cisco firewalls are a series of Hyper-V Host Servers. The servers sits on one of these servers and should the host machine fail then our servers will be seamlessly transferred from one host to the next. This means that Business Critical Systems, Applications and Sites continue to operate with no interruption to service.
Put into plain English this means that there are multiple levels of ‘Active Failsafe’ – backups that allow services to continue without interruption.
Behind the host machines, there are multiple San Storage servers. Setup in a Raid 50 configuration, (http://www.iscsi-raid.com/raid50.html) this contains the data and allows for up to 4 hard drives to fail before any data is lost. To put that into perspective we have been working with these SAN Solutions for a number of years now and only ever had 1 drive failure.
But what happens in the very unlikely event that there is a problem across the whole datacentre (earthquake, gas explosion etc etc) where your data is stored? We have full backups of data at a remote site. These backup daily and store your data for 7 days, meaning that in the event that a 'disaster' strikes, and then all servers fail, your data is simply restored from these backups. Furthermore, we also make a monthly backup which is stored at a second remote site.